Deep-Friends – An AI Generated SitCom
Authors: Daniel Vigild, Lau Johansson & Jonas Christophersen
13th March 2021
Read time: 5 minutes

If you ever wondered what AI-generated Hollywood SitCom scenes might be like, look no further, we got you covered. (If you were looking for an actual friends-generator, please feel free to visit the about section and send us an email - we love meeting new friends.)
Text-generation has been on everyone's lips (especially artificial ones) for a long time. As such we’ve sought out to try and generate new scenes for everybody's favourite Hollywood SitCom: Friends.
Let’s waste no time and get straight to generating scenes using our Deep Learning network! If you’re about to pitch a reboot-show to Hollywood executives as we speak it might come in handy.

Okay, so depending on your type of humour you might have found it funny or weird (maybe a bit of both). It would appear that machines have a very distinguished style of humour.
Nonetheless, some general tendencies seem to be shared between the human- and machine interpretation of a manuscript. Scenes are enclosed in square brackets, and (usually) contains a description of some setting. Similarly, dialogues are between characters of the New York inhabitants, and usually have an alternating structure between the participants of the conversation.
As such it seems that the Deep Learning network we’ve built and trained on the data is capable of identifying basic structures of natural language.
The structure of the natural language is made machine-friendly by the use of embeddings. Embeddings are high-dimensional numerical vector-representations of words. These embeddings are learned by the network by processing large amounts of texts - in our case the network has read lots of Wikipedia articles and transcribed Friends (and Seinfeld) scenes. Ultimately, words with similar meaning in the processed text will appear with similar values in this high dimensional space.
These structures of language can be visualized through the use of t-SNE (which stands for t-Distributed Stochastic Neighbor Embedding). It is a dimensionality reduction method, which enables us to view our high-dimensional space on classical 2-D graph. Take a look at the graph below to see the structure of the human language (or, as an AI would think this structure is). Note this graph is a select subset of the learned words, as there are a lot of words in the english language.
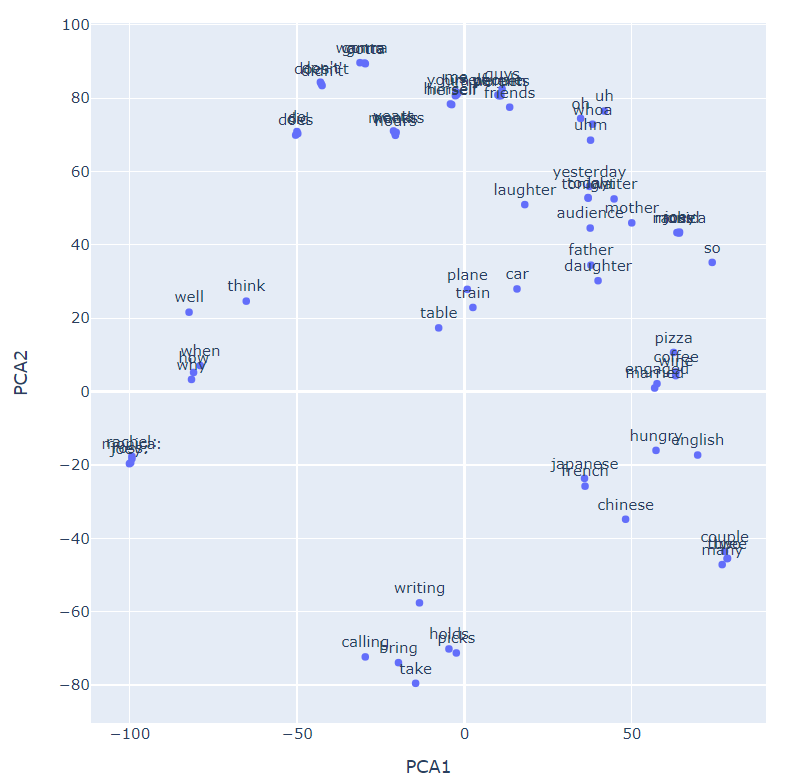
Alright, so the network seems to group some words together that have similar meaning, at least in the term of constructing sentences. Note how names are grouped, this is also the case for nationalities. It is also seen that verbs are generally closer to other verbs, compared to nouns which form their own groups.
If you wish to explore the embedding representation of the entire english language (or atleast the words encountered by our network) you can click around the embeddings below. If you highlight an area you can zoom into that region.
If you’re interested in the details of how this Deep Learning network was made, how it was trained, and which techniques were implemented to better its performance, you can read our research paper on the subject here. If you want to get into the details of the python-code you can visit out Github repository here.